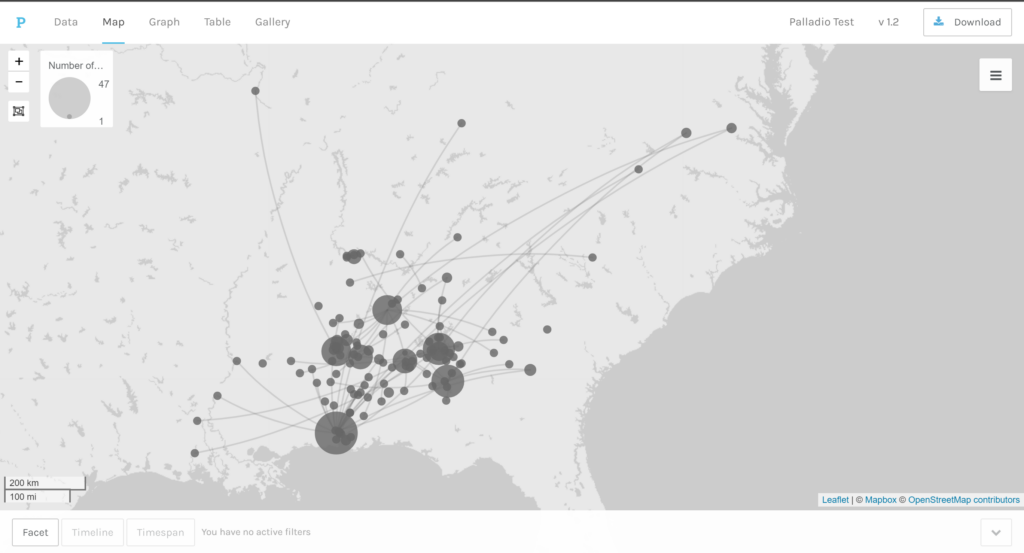
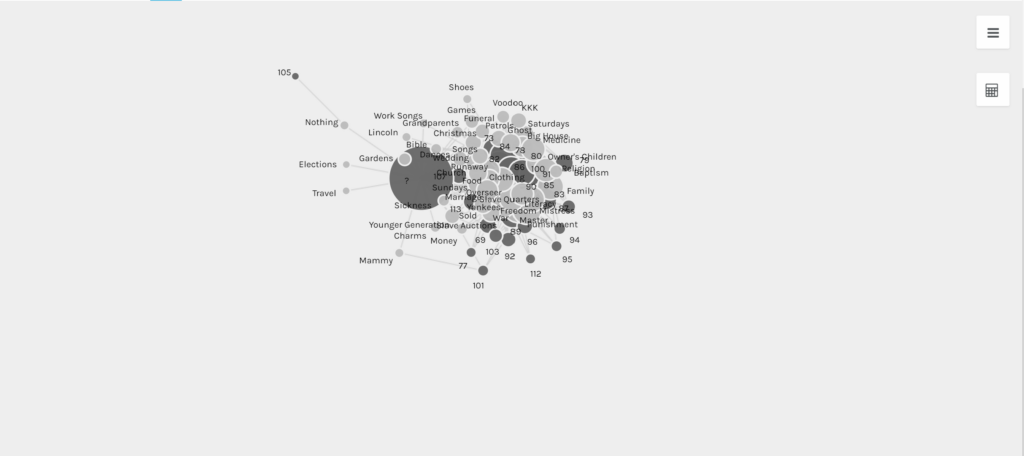
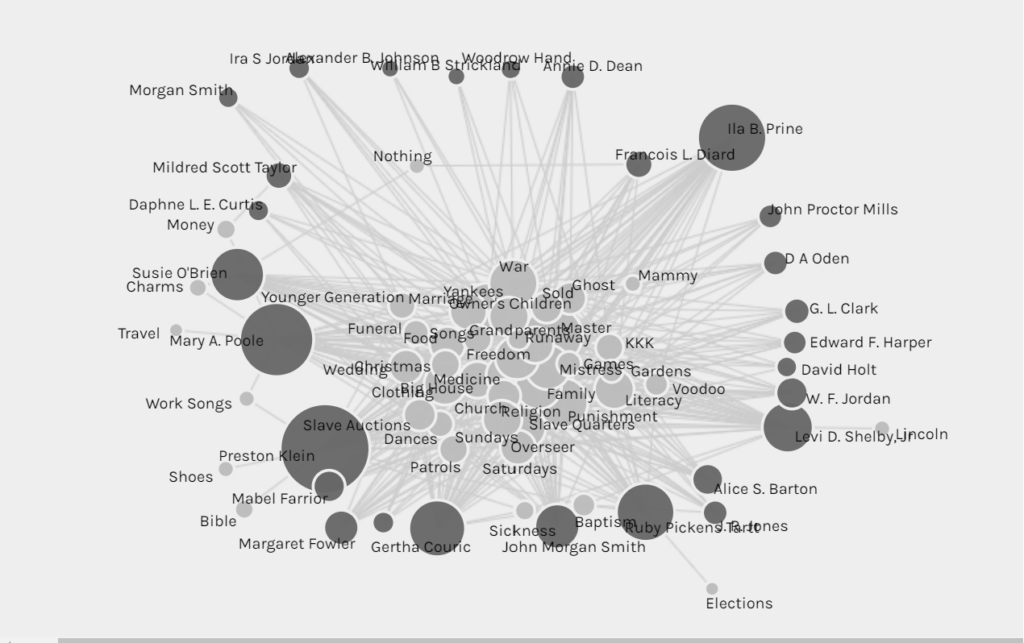
Using Wikipedia:
Wikipedia offers its users a unique opportunity to explore the talk and history pages of its articles. The exploration of the talk and view history pages gives users transparency on the creation of Wikipedia articles. Users can ultimately gain insight on the dialogue contributors have on article creation as well as the revising and editing process of Wikipedia pages.

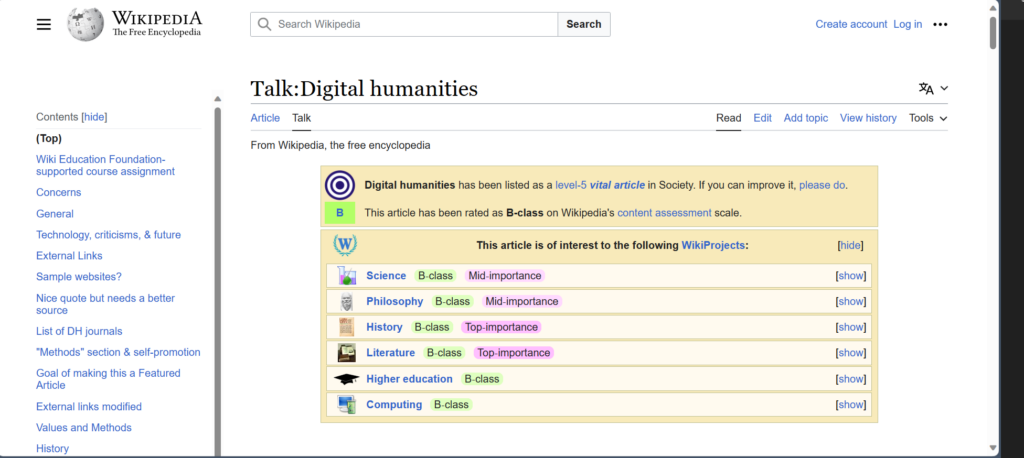
I utilized Wikipedia’s talk and history features in my exploration of Wikipedia’s digital humanities’ article. The talk feature allowed me to see the discussions contributors had over the content that was written. There were apparent issues related to the article’s organization. The article also had numerous contributors who engaged in a dialogue on making improvements to the article’s quotations, external links, neutrality, definitions and so on. Users are also allowed to view the biographies of the contributors. For instance, Skirden and Hectorlopez17 were top contributors for the current digital humanities article. They were both associated with Wikipedia projects like Wikipedian in Residence and the Electronic Textual Cultures laboratory. If the information is public, users can see the identified credentials of the key contributors and their associations. In regard to the history, I could see that the article was first created on January 30, 2006 by contributor Elijahmeeks. Since 2006, the page has evolved to include more information related to the digital humanities such as its definition, history, cultural relevance, project purpose, values and methods, criticism, references and external links.

That said, Wikipedia is not entirely perfect. It is open source which means anyone can access its entries. But, its transparency with features like their talk and history pages enables users to see how ideas related to their articles have changed overtime; therefore, enabling a reliance on user judgment.
Using AI:
Just like Wikipedia, Artificial Intelligence programs are not without their own problems and possibilities. Programs like ChatGPT have weaknesses in citing the location of information they utilize in their response. ChatGPT also generates fictional data points when it does not have enough information to answer an unfamiliar question. ChatGPT also has the potential to oversimplify complex issues due to a lack of human input as it is an AI. However, these flaws can be improved with the implementation of human feedback and plug-in creation.

According to Jon Gertner, AI companies have made moves to correct AI misinformation by using reinforcement learning with human feedback while the Wikimedia Foundation has created a Wikipedia based plug-in to redirect ChatGPT to Wikipedia for further information on a subject matter. For the most part, AI has the potential to work with users to answer questions in a conversational format that can initiate deeper inquiries into various subject matters. Also, the proposed improvements for AI can lead users into carrying their own scholarly research once AI can provide the necessary citations.